

Исследователи из Вашингтонского университета разработали новые алгоритмы, которые решают сложные задачи в области компьютерного зрения: превращая аудио клипы в реалистичное видео с синхронизацией по губам человека, говорящего эти слова.
Как подробно описано в бумага будет представлен 2 августа в SIGGRAPH 2017 Команда успешно сформирована очень реалистичное видео бывший президент Барак Обама говорил о терроризме, отцовстве, создании рабочих мест и других темах, используя аудиоклипы этих выступлений и существующие еженедельные видеообращения, которые изначально были на другую тему.
«Такой тип результатов никогда не был показан раньше», - сказал Ира Кемельмахер-Шлизерман, доцент в Школе информатики и техники имени Пола Аллена в UW. «Реалистичное преобразование аудио в видео имеет практические приложения, такие как улучшение видеоконференций для встреч, а также футуристические, такие как возможность вести разговор с исторической личностью в виртуальной реальности, создавая визуальные эффекты только из аудио. Это своего рода прорыв, который поможет осуществить следующие шаги ».
В визуальной форме синхронизации губ система преобразует аудиофайлы речи человека в реалистичные формы рта, которые затем прививаются и смешиваются с головой этого человека из другого существующего видео.
Команда выбрала Обаму, потому что технике машинного обучения требуется доступное видео человека, которому можно поучиться, и было много часов президентских видео в открытом доступе. «В будущем видео инструменты чата, такие как Skype или Messenger, позволят любому собирать видео, которые можно использовать для обучения компьютерных моделей», - сказал Кемельмахер-Шлизерман.
Поскольку потоковая передача аудио через Интернет занимает гораздо меньшую полосу пропускания, чем видео, новая система потенциально может завершить видеочаты, которые постоянно отключаются из-за плохих соединений.
«Когда вы смотрите Skype или Google Hangouts, соединение часто бывает зашумленным, с низким разрешением и действительно неприятным, но часто звук довольно хороший», - сказал соавтор и профессор Allen School. Стив Зейтц , «Так что, если бы вы могли использовать аудио для производства видео гораздо более высокого качества, это было бы потрясающе».
Повернув вспять процесс - подача видео в сеть, а не только аудио, - группа также потенциально могла бы разработать алгоритмы, которые могли бы определять, является ли видео реальным или созданным.
Новый инструмент машинного обучения делает значительные успехи в преодолении того, что известно как жуткая долина Проблема, которая преследовала усилия по созданию реалистичного видео из аудио. Когда синтезированные человеческие сходства кажутся почти реальными - но все же удается каким-то образом пропустить отметку - люди находят их жуткими или отталкивающими.
«Люди особенно чувствительны к любым областям рта, которые не выглядят реалистично», - сказал ведущий автор. Супасорн Суваджанакорн , недавний аспирант в школе Аллена. «Если вы не делаете зубы правильно или подбородок движется в неподходящее время, люди могут сразу заметить это, и это будет выглядеть фальшиво. Таким образом, вы должны сделать область рта идеально, чтобы выйти за пределы жуткой долины ».
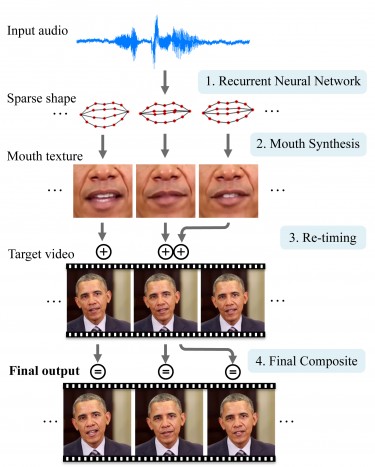
Нейронная сеть сначала преобразует звуки из аудиофайла в основные формы рта. Затем система прививает и смешивает эти формы рта с существующим целевым видео и корректирует время для создания нового реалистичного видео с синхронизацией по губам. Университет Вашингтона
Ранее процессы преобразования аудио в видео включали съемку нескольких человек в студии, повторяющих одни и те же предложения снова и снова, чтобы попытаться понять, как определенный звук соотносится с различными формами рта, что является дорогостоящим, утомительным и отнимает много времени. В отличие от Suwajanakorn разработали алгоритмы, которые могут извлечь уроки из видео, которые существуют «в дикой природе» в Интернете или в другом месте.
«Уже существуют миллионы часов видео из интервью, видеочатов, фильмов, телевизионных программ и других источников. И эти алгоритмы глубокого обучения очень требовательны к данным, так что это хорошо подходит для этого », - сказал Суваджанакорн.
Вместо того чтобы синтезировать финальное видео напрямую из аудио, команда решила проблему в два этапа. Первое включало обучение нейронной сети для просмотра видео человека и преобразования различных звуковых звуков в основные формы рта.
Объединяя Предыдущее исследование от UW Лаборатория графики и изображения Команда с новой техникой синтеза рта, они смогли реально наложить и смешать формы и текстуры рта на существующем эталонном видео этого человека. Еще одним ключевым моментом было дать возможность небольшого временного сдвига, чтобы позволить нейронной сети предвидеть, что докладчик собирается сказать дальше.
Новый процесс синхронизации губ позволил исследователям создавать реалистичные видеоролики Обамы, выступающего в Белом доме, используя слова, которые он говорил в телевизионном ток-шоу или во время интервью десятилетия назад.
В настоящее время нейронная сеть предназначена для обучения одному человеку за раз, а это означает, что голос Обамы - произнесенные им слова - единственная информация, используемая для «управления» синтезированным видео. Дальнейшие шаги, однако, включают в себя помощь в обобщении алгоритмов в различных ситуациях для распознавания речевого и речевого паттерна человека с меньшим объемом данных - например, для изучения требуется только час видео, а не 14 часов.
«Вы не можете просто взять чей-то голос и превратить его в видео Обамы», - сказал Зейтц. «Мы очень сознательно решили не идти по пути того, чтобы вкладывать чужие слова в чей-то рот. Мы просто берем настоящие слова, которые кто-то сказал, и превращаем их в реалистичное видео этого человека ».
Исследование финансировалось Samsung, Google, Facebook, Intel и UW Animation Research Labs.
Для получения дополнительной информации свяжитесь с исследовательской группой по адресу [email protected] ,
Tag (s): Ира Кемельмахер-Шлизерман • Школа компьютерной науки и техники им. Пола Аллена • Стив Зейтц